 |
|
|
English
| MAND atlas
| kartografie
↓ GTRP transcripties
MAND data: Goeman-Taeldeman-Van Reenen-project
ook GTRP: CD-ROM | items | plaatsen | sprekers | transcripties per plaats | per item
Het Goeman-Taeldeman-Van Reenen-project betrof
Voor een indruk van gesproken dialect (NB: niet-GTRP) kan worden verwezen naar de "Sprekende
Kaart" op de website van het instituut.
|
|
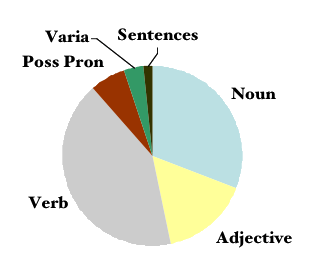
De 1876 items van de afvraaglijst bestaat voor het merendeel uit naamwoorden en werkwoorden maar ook uit 22 zinnetjes en 106 adjectivale woordgroepen. De database bevat daarmee ruim 1,1 miljoen eenheden. Alle elementen (als lidwoorden en persoonsvormen) apart gerekend, met daarbij nog de varianten-opgaven, brengt de omvang van de database op een 2 miljoen 'woorden'.
|
Meer in nieuw venster: motivatie en historie afvraaglijst etymologie opnameplaatsen gif opnameplaatsen html veldwerkmethode (K)IPA-codering IPA belang dialect-genoom Meer over het belang en de cd-rom: Respons 2003 |
|
Alle opnames zijn 'nauw' getranscribeerd volgens het "International
Phonetic Alphabet" (IPA) als onderwezen door
dr. P.Th. van Reenen aan de Vrije Universiteit, Amsterdam. Daarbij
werd door de studenten gebruik gemaakt van een licht aangepaste
versie van W.H. Chapman's "Introduction to Practical Phonetics" (van
het Summer Institute of Linguistics).
Speciaal voor dit project werd het "Keyboard IPA" (KIPA, K-IPA)
ontwikkeld: een codering in toetsenbord-karakters (in de lage
ASCII reeks) van het IPA. Het is een uiterst flexibel
en praktische codering gebleken. Bij dezen een oproep de K-IPA
codering (met voordelen ten opzichte van het latere (X)SAMPA) ook te
gebruiken bij uw projecten. → K-IPA
|
veldwerkmethode
IPA-codering IPA SIL |
|
De geluidsopnames zijn inmiddels gedigitaliseerd. Eventuele
compressie wordt nog nader bekeken op kwaliteitsverlies.
|
contact |
Voor een indruk van gesproken dialect (NB: niet-GTRP) kan worden verwezen naar de "Sprekende
Kaart" op de website van het instituut.
Samenwerking |
top |
Het project ontstond uit een samenwerking
van het Meertens Instituut-KNAW met
Medefinanciering kwam van
Data-kenmerken |
top |
|
Hieronder volgen enkele grafieken die betrekking hebben op de
betrouwbaarheid en de validiteit van de gegevens. (De grafieken zijn
bij gebrek aan beschikbaarheid van gegevens bij aanmaak gebaseerd op
de opnames verzorgd door het Meertens Instituut en het Nedersaksisch
Instituut.)
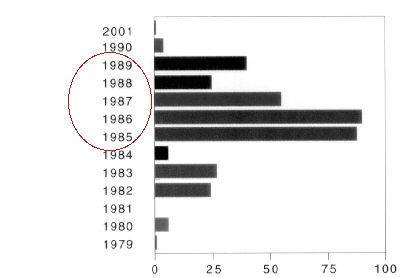
Allereerst volgen gegevens met betrekking tot de aantallen opnames en transcripties: per jaar, per veldwerker, per transcribent.
De Belgische opnames zijn alle gemaakt tussen 1990 en 1993. |
top |
|
|
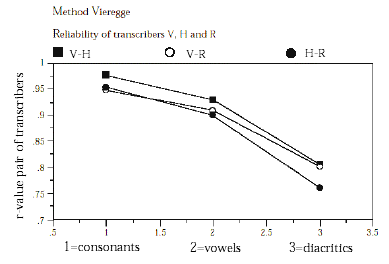
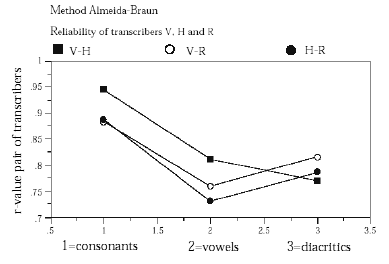
Vervolgens enkele grafieken (uit dezelfde studie, Goeman 1999, hoofdstuk 2) die mee helpen duiden dat de opnames een goed beeld van de dialecten geven. Voor toelichting en meer overwegingen (bijvoorbeeld over de spreekstijlen tijdens het veldwerk): volg de verwijzing. Eerst een grafiek van de kwaliteitsoordelen door de veldwerkers waarvan Goeman 1999 vermeldt (hoofdstuk 2, p. 70) dat er geen significante samenhang bestaat tussen deze oordelen en informantkenmerken.
De verdeling van plaatsen naar grootte loopt min of meer gelijk op met de verdeling zoals destijds gold voor Nederland.:
|
|
Genoemde studie Goeman
1999 voorzag de sprekers van het project van een
beroepsprestige-index volgens UltÄe & Sixma 1983 ("Een
Beroepsprestigeschaal voor Nederland in de Jaren Tachtig. Mens &
Maatschappij 58: 360-82) die zich baseerden op het sociaal prestige
in de tijd van publicatie. Waar geen beroep werd opgegeven werd de
index van de partner (waar mogelijk) genomen.
Uitvoerders |
beroepsprestige- conversietabellen |
De opstellers van de vragenlijst waren
De coÜrdinatoren van het veldwerk waren
Projectondersteuning kwam van
Veldwerkers en transcribenten voor Nederland waren
Voor België zijn dat geweest
Voor Friesland zijn de opnames
Publicaties |
naamgevers
top |
|
Hèt artikel om naar te verwijzen is:
Goeman, A. en J. Taeldeman 1996 "Fonologie en morfologie van de Nederlandse dialecten. Een nieuwe materiaalverzameling en twee nieuwe atlasprojecten." in: Taal en Tongval 48: 38-59. Het webadres om naar te verwijzen is: http://www.meertens.knaw.nl/projecten/mand
Naar de data kan verwezen worden middels:
Voor publicaties rondom de data → MAND atlas → publicaties
Voor enkele voorbeelden van het belang van de data → belang
|
top |






GTRP: CD-ROM | items | plaatsen | sprekers | transcripties per plaats | per item
English | MAND atlas | kartografie ↑ GTRP transcripties